Trending AI
Urban Dictionary defines hype as ‘Wild and flashy valuing style over substance with a breakneck pace’. Another word is a fad. A strategy where a product is publicized as the thing everyone must have, to the point where people begin to feel missing out without it. History provides a good starting point to discern the present state. So, to determine whether Data Products are result of hype, it is essential to examine the evolution of the data and analytics industry, as history serves as a valuable tool for understanding the current state.
Big Data Revolutionizes Financial Markets - The Wall Street Journal, 2012
Investment Firms Embrace Big Data Analytics for Better Returns - Bloomberg, 2013
World of data
Over a decade ago, Big Data dominated headlines, but its popularity has since waned. As I reflect on this topic, memories resurface of the enthusiastic migration from IBM Netezza to Hadoop Big Data, as if it held the ultimate solution to all our problems. Such hype cycles often arise from excessive optimism about new technologies, leading people and companies to get carried away with the allure of the next big thing, driven by the fear of missing out.
However, the reality of any new hype cycle or technology lies somewhere in the middle; it cannot magically address all the challenges one hopes to overcome. When Big Data emerged, organizations made significant efforts to transition from existing tech stacks, like Teradata and SQL Server, only to find themselves grappling with longer query run times in the new environment. The newer technologies are not inherently flawed, but the real challenge stemmed from those who hastily moved to this new shiny thing without making heads or tails of it.
With the advent of better technology, faster internet, and acceleration of digital connected experiences aka Internet of things, caused for data deluge and resulted in the need for tools and techniques to synthesize this raw data and produce meaningful/actionable insights out of it. This gave birth to another hot new thing, which was data scientist. Our beloved statisticians turned out to be data scientists, then it turned to machine learning, and now AI.
The convergence of advanced technology, faster internet, and the proliferation of digital connected experiences, such as the Internet of Things (IoT), has led to "data deluge." Consequently, this surge in data necessitated the development of tools and techniques capable of processing and extracting meaningful and actionable insights from this raw information. This marked the rise of a new and exciting field known as data science.
Initially, data science transformed the role of traditional statisticians, empowering them to adapt to the changing landscape and become data scientists. As the field evolved further, it incorporated machine learning, enabling data scientists to employ algorithms and models to discover patterns and make predictions based on data.
Today, we witness another transformative shift as data science integrates with artificial intelligence (AI). AI takes data analysis to new heights, allowing systems to learn from data and make autonomous decisions. This continuous evolution reflects the dynamic nature of technology and how the quest for unlocking the potential of data continues to shape the landscape of innovation.
In each new cycle , we observe that easily implementable aspects change rapidly. In the evolution of data science, one consistent element that has undergone frequent transformations is the job titles. The roles have evolved from statisticians to data scientists, then to machine learning scientists, and now to AI leaders. Now, we are talking about Prompt Engineers as its own field. I’m going to resist my urge to make any comments around that. As with any cycle, time will tell.
Data Scientists: The New Rock Stars of Tech - TechCrunch, 2016
Data Scientist Positions Among the Fastest Growing in the Job Market - CNBC, 2018
What doesn’t change and where should one direct focus?
Through all these advancements, the fundamentals of data science have remained constant. You still need to understand the concept behind Bayesian statistics, linear regression, and the probabilities vs possibilities. The newer toolkit makes it easier to build models or draw insights, but one must prioritize learning ‘first principles’. First principles help you reverse engineer and break the complex problems into basic elements and build it back from ground up. Elon Musk and Charlie Munger are renowned for their consistent application of first-principles in all their endeavors.
This brings to data products…
What is a data product?
Data product is a product that facilitates an end goal through the use of data - DJ Patil, former United States Chief Data Scientist.
While this definition captures the core idea, it may be too broad for our specific understanding. Let's consider an example to illustrate this point. Take Meta Quest Pro, an advanced virtual reality headset that heavily relies on user data to deliver its ultimate goal: providing a virtual reality experience. Can we categorize Meta Quest Pro as a data product? Probably not. In this case, Meta Quest Pro is a consumer product designed primarily to offer virtual reality experiences, utilizing data as a means to enhance its functionality rather than being a data-centric product itself.
In the same example, while the Meta Quest Pro itself may not be considered a data product, the Meta team could indeed have separate analytics products or tools that gather and analyze user data to gain insights into user behavior, preferences, and overall device usage. These analytics products can be considered as data products since their primary function revolves around data collection, analysis, and generating valuable insights to improve user experience, refine product design, and make data-driven decisions.
My definition of data product (data science lens)
A product whose primary objective is to transform the raw data into meaningful and actionable insights for its users, while adhering to the principles and lifecycle of product management.
We must unpack two elements of this definition: 1) The MA Framework (Meaningful and Actionable), and 2) The principles and lifecycle of product management.
The MA Framework
-
1. Meaningful insights should help users gain clarity, make informed decisions, and derive valuable insights from the data. Your data product should effectively answer specific questions related to the problem or objective at hand.
-
2. Actionable insights takes it a step further by providing recommendations that users can act upon to drive positive outcomes. It goes beyond fact reporting or descriptive statistics.
Not to mention, the above should be supported by having accurate, reliable, and timely information. Without it, your data products are just a garbage.
Below is an example to differentiate Meaningfulness and Actionability.
Business : We would like to understand the customer segments for upcoming marketing campaign focused on movers to capture their share of wallet.
Data Practitioner 1 : Here is the raw excel export of all the customer data and demographic information.
Data Practitioner 2 : Here is the dashboard with collection of charts and graphs on different customer segments available; Doesn’t provide any context or annotations.
Data Practitioner 3 : Here is the data product (agnostic of tools) that analyzed all the existing customer data, and identified particular segments of the population that could benefit this marketing campaign based on their past purchase behavior. These visuals also represent new, and lapsed customer segments who could potentially benefit from this marketing event.
The above conversation is as real as it could get. As you may agree, the DP1 & DP2 are just data pulling machines, we don’t see any elements that help users of this data to gain clarity or nudge for meaningful decisions.
However, the #DP3 not only analyzed all the existing information, but also provided recommendations on what could be the potential next steps. We see guidance and persuasion of business teams to move in the right direction. It has both meaningful and actionable information.
One could argue to classify the #DP3 example as analytics or insights work, which is true if we consider just the first part of the definition. What truly qualifies it as a data product lies in the incorporation of the second element of the definition - ‘adhering to the Principles and Lifecycle of product management.’ This element distinguishes it as a fully-fledged data product rather than just an analytics output or insights presentation.

The MA framework works very well with data science and analytics problem statements and might not squarely fit to other areas like software applications, APIs, etc. which by the way are data products too.
Data Products → Data as a Product
The inherent confusion on what fits to be a data product comes from its broad scope and lack of specificity. By making a slight adjustment to the verbiage to ‘Data as a Product’ significantly narrow down the scope and better categorize the offerings that fall under this concept. So far, we have covered data science evolution, and touched on the first element of the ‘data product’ definition. Now, we are going to focus on the second element, ‘Principles and lifecycle of Product Management’.
The Principles and Lifecycle of Product Management
You’ll find a ton of material covering core principles of Product Management. So, I’m not going to belabor the boiler plate. In essence, the core philosophy of PM centers around understanding and fulfilling customer needs and wants, emphasizing continuous iteration and improvement, driven by data-driven decision making, and the value prioritization to deliver successful and customer-centric products. From a tactical perspective, this includes OKRS, roadmaps, and timelines to bring alignment, avoid scope creep and drive the focus to achieve stated objectives.
The true beauty of ‘data as a product’ comes when we embrace the principles of product management as a framework around data and analytics. While the first-principles of data and analytics remain valid, adopting a product mindset adds a valuable layer of perspective and focus to the process.
So, can we categorize all your 100+ Tableau dashboards and 50 different statistical models as data products? Fortunately not! To determine if something qualifies as a data product, we should begin with the MA Framework: Is the data meaningful and actionable for its intended audience? Secondly, we need to consider whether the product addresses user needs and wants, if it aligns with OKRs, if there is a roadmap in place, and if there are plans for iterative improvement and evolution from the MVP. These are essential questions to ask before labeling something as a data product.
✻✻✻✻✻
.jpeg)
Sravan Vadigepalli
Sr Director, Data Products & Applied AI at Lowe's
Sravan Vadigepalli has spent the past decade building and curating data analytics teams in the retail industry. He specializes in translating data into insights and applications of Machine Learning/AI models to ever evolving retail space. Sravan did his MS in MIS from Oklahoma State University and an MBA from University of Illinois Urbana Champaign. Outside of work, Sravan is a self-proclaimed long distance endurance runner.
Approaching Generative AI with a Focus Towards Data and AI Governance
In God we trust, all others must bring data - W. Edwards Deming
It was an icy morning at Cape Canaveral, Florida on January 28, 1986 and all eyes were on NASA’s historical space shuttle launch, the Challenger, promising the dream - Space for Everyone. The dream quickly turned into a tragedy when the space shuttle exploded just 73 seconds after lift off, killing all seven crew members aboard. This disaster shook the entire nation and the space shuttle program was grounded for nearly three years. It was soon learned that the explosion was caused by the failure of a tiny rubber part, commonly known as the O-ring. The O-ring’s function was to seal the joints and prevent hot combustion gasses from escaping from the inside of the motor.
What went wrong with the O-rings on the fatal morning? The record-low temperatures on the launch day stiffened the rubber O-rings, reducing their ability to expand and seal the joints. Ignoring the available data for decision making and owing to the extreme external pressures, where the space agency had to innovate and prove its space dominance, induced the disaster. The temperature on the launch day was 36 degrees. Investigation into the horrid incident revealed that the O-rings were consistently malfunctioning under 53 degrees 1 . Superficial look at the O-ring performance data from previous 23 launches would not reveal a pattern as the O-rings failed both in higher and lower temperatures. There was also the issue of lack of data as there were no prior launches where the ambient temperature was below 53 degrees. This was also a clear case of a sample selection problem. A statistical analysis on the available dataset would have clearly demonstrated a correlated probability of successful launches at higher temperatures. The challenger disaster gives us a great deal of insight into the critical importance of data-driven decision making.
This may sound like an extreme example caused by the failure of data-driven decision making. However, whether it is introducing a new product, launching a new marketing campaign, expanding to newer markets, data is extremely critical to decision making and can make or break the future of an enterprise. In a recent example, Zillow’s iBuyer - a machine learning driven home buying service - was shut down due to higher-than-anticipated conversion rates and unintentionally purchasing homes at higher prices. Rich Barton, the CEO and co-founder of Zillow 2 said in a letter to shareholders,
“Put simply, our observed error rate has been far more volatile than we ever expected possible and makes us look far more like leveraged housing traders than the market makers we set out to be. We could blame this outsized volatility on exogenous, black swan events, tweak our models based on what we have learned, and press on.”
Similarly, Tay - an AI chatbot released by Microsoft - was taken offline 3 after dashing out a slew of controversial tweets, a testimony to prove the importance of data and AI governance.
Just a decade ago, one of the common challenges faced by enterprises was the lack of availability of data, hampering business growth. Lack of data availability meant that crucial business decisions weren’t yielding the right impact. Fast forward to today, storing vast amounts of data and access to 3rd party data is no longer proving difficult or cost prohibitive, thanks to the exponential evolution of cloud computing and data democratization that alleviated the data availability concerns. However, having access to data is very different from making sense of the collected data. From edge devices, IoT sensors, mobile, social media and user events, enterprise data sources continue to expand exponentially. Owing to the exponential growth in data, IDC predicts that the global data growth will reach a massive 175 zetabytes by 2025. While the data availability is no longer a concern, the primary challenge lies in ensuring data integrity, consistency and unified data governance. It’s no doubt that data is the new gold. However, organizations can hit gold only after prospecting, mining, curating, extracting, enriching and refining the data mine, while also ensuring the right data is used in the right context at the right time for business decisions.
Traditional data warehouses predominantly operate on structured data, offering deterministic data analytics. In contrast, a modern enterprise data lake house encompasses both structured and unstructured data, serving as a foundation for predictive data analytics. This opens up innovation avenues that were once thought impossible. The modern discipline of Generative AI is a subset of deep learning. While a traditional discriminative AI is trained on a labeled dataset to help cluster, classify, or predict the next best action, a generative AI is trained on massive amounts of generally available data—text, image, audio, or video—also known as the foundational model to generate new data.
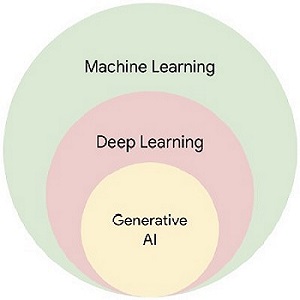
There are five key considerations as enterprises explore and experiment with Generative AI;
-
5. Establish Generative AI KPIs : As with any technology investment, it is imperative to establish a set of key performance indicators (KPIs) to measure, track, and report on the value of Generative AI. Some key metrics may include productivity improvements, output quality and relevance, accuracy, and business impact.
-
4. Picking the Right Data: The choice of data source is critical for training and fine-tuning a generative AI model. A good data source should be representative of the real world, free of bias, and large enough to provide the model with a variety of examples to learn from. This will help to ensure that the model produces accurate, reliable, and explainable results.
-
3. Identify a Business Domain: : It is imperative to identify a specific business function that can be significantly improved by Generative AI. For example, Generative AI can be used to improve associate productivity by reducing repetitive tasks or unlocking and activating large corpus of data to glean insights.
-
2. Responsible AI: It is of paramount importance to foster a culture of responsible innovation in order to ensure the long-term success of any AI initiative. While generative AI holds the potential to transform business functions, building AI applications that are transparent, fair, secure, and inclusive can reinforce customer trust while also mitigating unintended bias.
-
1. Data and AI Governance: In most technology discussions, governance is often overlooked or treated as an afterthought. However, it is prudent for enterprise leaders to establish data and AI governance before embarking on any AI initiatives, including Generative AI. AI curiosity must be well-governed from the outset to ensure that AI applications continue to guarantee consumer data privacy, ethical use, eliminate bias, and provide control.
Some Generative AI use cases that enterprises across any industry vertical can leverage to realize quick value add include:
-
Associate Productivity:Generative AI can serve as a collaborator for a number of everyday tasks and repetitive activities such as routine email management, organizing calendars, identifying trends in data sets, writing and even for learning and development.
-
Customer Experience: Generative AI can augment traditional customer service capabilities such as chatbots to offer smoother self service and personalized customer experiences.
-
Data set Generation: : Generative AI can help generate synthetic multi-modal data sets for various AI/ML use cases that can significantly improve the model quality.
-
Personalized Marketing: Leveraging GenAI capabilities, unique media content can be generated from simple prompts for e-commerce, marketing campaigns or web design. It can also be used to create personalized marketing campaigns that are more likely to resonate with individual customers.
-
Code Generation: IT teams can accelerate application development and code quality by automating code generation and recommendations
While the technology landscape surrounding Generative AI will continue to evolve and mature, it is only a matter of time before it becomes widely adopted. The right approach for each organization will ultimately depend on its unique needs and goals. By building a strong data foundation with the right governance strategy and a focus on responsible AI use, enterprises can strive to achieve consistent and long-term success.
✻✻✻✻✻

Sathya AG
Principal Architect, Google
Sathya is a tech evangelist, blogger and a practicing enterprise architect with a passion towards advocating value-driven digital transformation for enterprises. He brings over 17 years of experience across software development, consulting, sales and value advisory. In his current role as a Principal Architect at Google, he advises select enterprises on digital transformation strategies.